Hydra, Theoretical Physics' compute cluster
 Hydra: Some of the compute nodes Hydra: Some of the compute nodes |
Hydra is a linux-based, 15 TFLOP Beowulf cluster consisting of 143, dual-cpu, multi-core, Intel-CPU based machines for people in Theory who need large amounts of CPU time. We have a total of 2,200 CPU cores on which to run programs, either MPI-based or normal "serial" programs. You can connect via SSH or x2go (a virtual desktop) or RDP (a virtual desktop). Please email jonathan.patterson@physics.ox.ac.uk if you want to connect via RDP - I have to enable it for you. RDP needs to be tunnelled through ssh or you need to connect via the Physics RDP gateway. If you want to use x2go or RDP and have environment modules (see below) that you want to use, then you'll need to run "source startmodules" from your terminal session in the virtual desktop to get them working. ssh is the ideal way to connect if you don't need graphical output on your screen, and that's how most people use the cluster. There are various scientific libraries/bits of software installed but you can always ask for whatever you want on there. You can get an account if you're in the Theory department and your supervisor says you can have an account, so get in touch with them or contact Jonathan Patterson ( jonathan.patterson@physics.ox.ac.uk ) direct for more info/to setup an account. Hydra is meant for the running of multiple programs in parallel on compute nodes via the queueing system. Running a single program directly on it will not be any faster than running it on your desktop. |
HARDWARE
The machine lives at the Begbroke Science Park and the OS used is Ubuntu 18.04.
Each node is connected by standard gigabit ethernet for normal network tasks like NFS (over which your home directories are connected), and for MPI messages if you're running a parallel MPI program.
If you want to run a "normal" (ie. non-MPI, non-OpenMP) program lots of times with different parameters, ( a lot of you do exactly that ) then I have a program which can make that pretty easy - "multirun". More information is available here or please email me for more info. It's easier than converting your current "normal" program to MPI.
We've got 57TB of disk storage kept in a ZFS storage array. This is backed up every day off-site, and there are backups every hour on-site as well. So if you want to undo a file change, just email me. We also have a distributed filesystem ( 95 TB, /mnt/extraspace ) for people who need faster access to their files.
Please avoid storing huge numbers of files in a single directory. It might seem easy and convenient for your program to store half a million files in a directory but doing anything in the directory will become very very slow. Avoid anything more than a thousand.
GPUs
Attached to this cluster are some machines for GPU work, split into different queues.
gpushort is for quick jobs/debugging, gpulong is for longer running jobs.
There are also two other GPU queues, kocsisgpu and heraclesgpu, but they are reserved for use by particular groups in Theory. You can run on heraclesgpu, but if a priority person needs to use it then your job will be stopped.
The command showgpus will list which nodes have GPUs, what models they are with how much memory, which ones are currently available to be used, and which queue they are in.
Please feel free to ask me if you have problems getting things going, as it can be a bit tricky. To make sure that you get a whole GPU card to yourself on these, please submit the job as:
addqueue -q gpuQueueYouChose -s --gpus numberOfGPUsYouWant --gputype optionallySpecifyTheType -m CPURamYouNeedInGB./yourProgram,
eg. addqueue -q gpulong -s --gpus 1 --gputype rtx2080with12gb ./myProgram
or
addqueue -q gpulong -s -m 4 --gpus 1 ./myProgram
if you don't mind which GPU you get.
If you need to compile on the GPU machines then you can use these by sshing to them, eg. "ssh gpu01", loading the cuda module ( module load cuda ), compiling on one of the gpu machines, then returning to hydra, and submitting to the gpu queues.
WHERE TO KEEP FILES
There are two storage areas on Hydra. There's your home directory, which is backed up, and there is /mnt/extraspace, which is the distributed filesystem, and is not backed up. /mnt/extraspace should be used for when you have to write large amounts from multiple programs at the same time as it should be less prone to getting overloaded than the home directories. Please don't keep important files in it though, as it is not backed up (did I mention that already?!), is slightly 'experimental' and therefore should not be trusted with your most important files. It's an 'overspill' area or for when you have to write a lot, fast.
TRANSFERRING FILES TO THE CLUSTER
I suggest using rsync or scp to transfer files - these are available on linux/OS X and there are scp clients for windows. Typical usage would look like:
rsync -axv localDirectoryName/ myusername@hydra.physics.ox.ac.uk:remoteDirectoryName/
scp -rpv localDirectoryName/ myusername@hydra.physics.ox.ac.uk:remoteDirectoryName/
To transfer the contents of a directory (and any directories in it) over to a subdirectory of your home directory. Feel free to ask me if you have any questions about transferring files.
Transferring back would look like:
rsync -axv myusername@hydra.physics.ox.ac.uk:remoteDirectoryName/ localDirectoryName/
COMMONLY USED COMMANDS
There are some commands which are specific to the queueing system. These are detailed below but they are also available in a one-page cheat sheet for your referral later on.COMPILING
The GNU compilers are installed by default (no environment module needed)
If you're compiling an MPI program, the following commands will call the compiler, linking in the necessary MPI libraries (once you have the openmpi module loaded, as mentioned in SOFTWARE LIBRARIES below):
mpicc, mpicxx, mpif90.
SOFTWARE LIBRARIES
There are lots of libraries/programs available. We use the "Environment Modules" software to manage which ones you want to be available, so:
module avail lists what software modules are available
module list shows which ones you have loaded
module load moduleName loads a module,
eg. "module load openmpi" selects the OpenMPI library
"module load fftw/2.1.5" would load version 2.1.5 of the fftw libraries, and just "module load fftw" would load the default version.
module unload moduleName removes a module
module initadd/initrm/initlist adds/removes/lists which modules are loaded each time you login. So if you use something all the time, add it using that.
Numerous other libraries are available - "module avail" to list them, so have a look in there to see if the library you want is available, but if not I can install it.
Feel free to email me (jop@astro.ox.ac.uk) if you have any problems compiling.
PYTHON LIBRARIES
The OS has python3 installed. You're bound to want to install modules, however. Most python modules are available using "pip", and you would install them with "pip install numpy" for example. This would install them system-wide, however, which you will not have the filesystem permissions to do. You can install any modules you want in your home directory, however, by adding "--ignore-installed --user", so eg. "pip install --ignore-installed --user numpy" would install numpy in your home directory.
Sometimes people need to keep multiple python environments. For example, project1 may need a specific version of numpy but project2 needs another version. You can keep separate python environments with their own modules using a virtualenv. There are numerous tutorials on this out there, and the homepage for virtualenv is https://virtualenv.pypa.io/en/latest/ . This is a good way of managing more complicated python setups.
If you have any problems with any of the above, just let me know and I can help.
USING MPI
MPI is "Message Passing Interface" - library functions for sending & receiving messages between processes. Typically, programs use these to exchange information about which process should be doing what to what - distributing the work.
The default mpi module is openmpi. If you want to use MPI communication in your program, please add that module to your environment "module initadd mpi".
THE JOB QUEUE
We use the slurm queueing system, with some extra queueing/display software I've written which runs on top of it in an effort to make sure everyone gets a fair share of time on the cluster. There is a flexible limit to the number of cores someone can be using at a time, which is determined based on how busy the queue is. It's normally around 300. There are 3 queues in the cluster - "short" (for quick runs or tests), "bigmem" (for jobs needing lots of memory) and "long" (the default queue).
"n -t" will show you what compute nodes there are, how much memory they have, and how busy they are.
MEMORY
Jobs are allocated 0.1 GB of RAM unless you ask for more with the -m flag to addqueue (see below). If you exceed the memory limit, you'll get a message in the job's output file to say so, though sometimes it will just say "Killed.". You can check how much memory it used with the q command.
SUBMITTING YOUR JOB TO THE QUEUE
You can use q -tw 1 to give a list of the compute nodes and how many cores/GB they have free right now. This will tell you what kind of job it's possible to run right now.
addqueue -c "runtimeEstimate or comment" ./myProgramName myParameters
You can just type "addqueue" to get the different options, but here are some common ones:
eg.
addqueue -c "2 days" -n 2x8 ./doSomeAnalysis
will submit your program "doSomeAnalysis" to the default queue, requesting 2 compute nodes with 8 cores on each (so 16 processes are started). You can also use the runtimeEstimate to add your own comments about the job - parameter numbers, maybe, to keep track of which job is which.
addqueue -c "1 week" -m 3 ./doSomeAnalysis
would run a single-process (non-MPI) job with 3GB RAM allocated to it
OR
addqueue -c "1 week" -n 31 ./doSomeAnalysis
would submit a 31-core job to the queue with no mention of how many cores to run on each compute node - so they'll be allocated wherever the queue sees fit. It only really matters how the cores are allocated if your job uses a lot of MPI communication, in which case you'll want as many of them as possible running on each compute node because if the MPI traffic has to go over the ethernet it will be quite slow.
Once you've submitted it you'll see the job number which was allocated to it.
OpenMP
If you are using OpenMP then, to make sure your program runs happily alongside others, you should use the -s option for addqueue, as below. This will set the OMP_NUM_THREADS environment variable so that OpenMP uses the correct number of threads.
addqueue -s -c "test" -n 1x8 myProgram myProgramArguments
which would tell OpenMP to use 8 cores.
If in doubt, feel free to ask me.
Mixing OpenMP and MPI
If you want to use a mix of OpenMP and MPI, here's one way of doing it. You can make a script called, eg. myrun.sh, containing:
#!/bin/bash
export OMP_NUM_THREADS=4
/usr/local/shared/slurm/bin/srun -n 6 -m cyclic --mpi=pmi2 myProgram myParameters
Then make it executable, eg. chmod u+x myrun.sh, and submit it with addqueue -s -n 2x12 -q cmb ./myrun.sh
All this would, for example, allocate 2 nodes with 12 cores each to run the job, then start 6 processes spread over the 2 machines, with each using 4 cores.
Mathematica, Matlab
which matlab or which mathematica will tell you where the actual program is, then you can use that in:
addqueue -n 1x3 -l -s /pathtoprogram/math -script scriptname.m
or
addqueue -n 1x3 -l -s /pathtoprogram/matlab -r functionName
Would reserve 3 cores on the same compute node, and only run 1 occurance (-s) of mathematica at a reduced priority (-l), telling it to run your script scriptname.m
With Matlab specifically, I've seen cases where using parfor or allowing matlab to use all the cores available actually slows the code down, or at least runs at the same speed. So it's worth trying with the -singleCompThread option to matlab. If this runs at the same speed as without it, then please use it, otherwise matlab will use more cores than it needs to. Let me know if you'd like some help with this. If you're using the parcluster routine, and launching multiple matlab jobs at the same time, please be aware of this likely problem.
CHECKING YOUR JOB
The command q will list your jobs in the queue.
If you have X-windows forwarding enabled, or are using an RDP connection to hydra, then you will get a graphical GUI showing you the jobs. There are various buttons to play with, and the main list of jobs shows all sorts of job info, including current usage stats for the jobs - how many cores, memory GB, diskIO, etc it's using right now. |
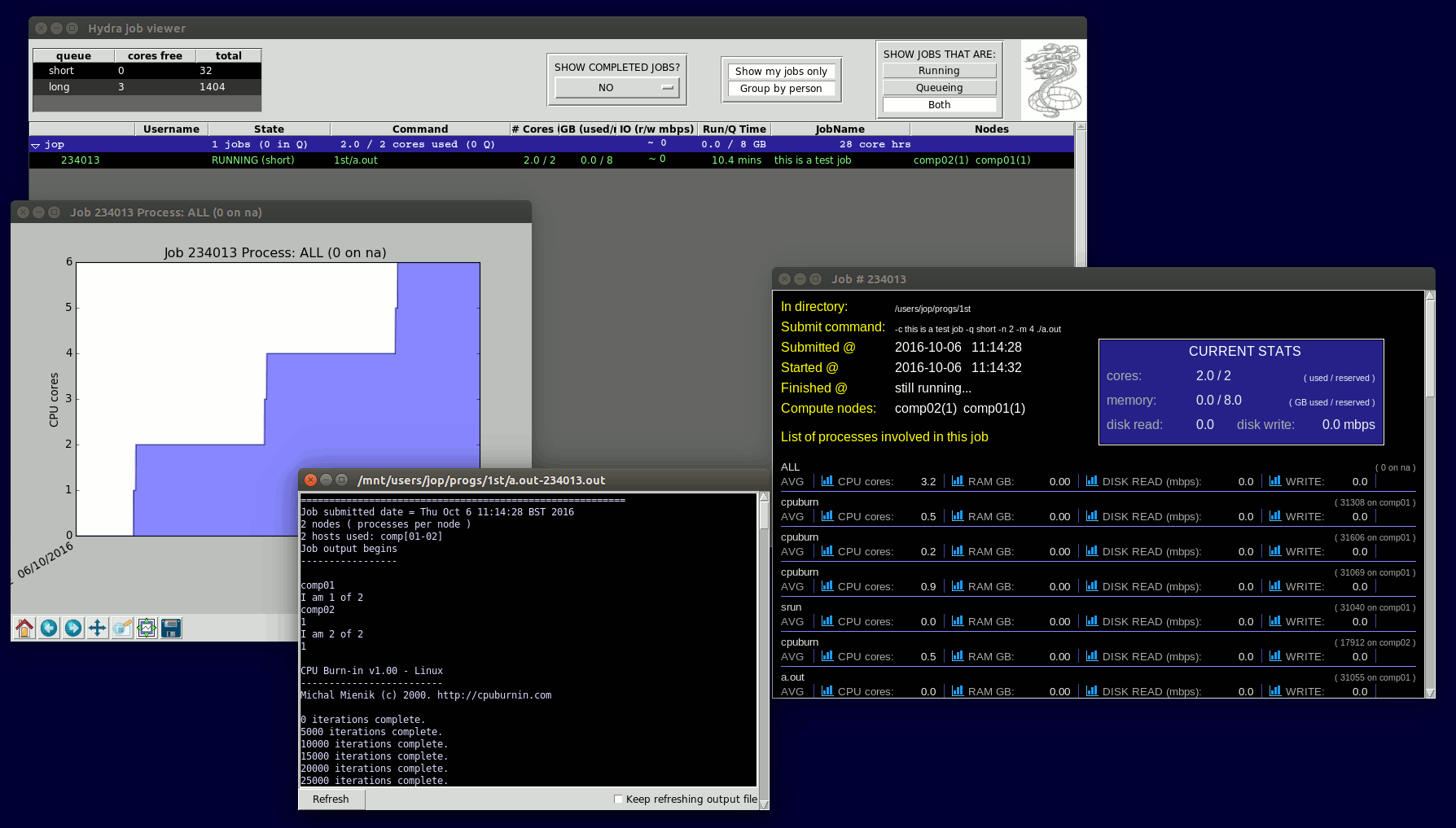 |
You can then double-click on a job to show the job's output file, or right-click to get various options, eg. show job statistics, cancel job, etc
If you select "show job stats", then you will get a window showing CPU, MEMORY, DISKIO usage, and you can click on the icons there to graph these over time. You can use this to check that your job ran efficiently, had enough memory, etc.
If you don't have X-windows on, or you type "q -t", then you'll get a text-only version.
You can check the output (stdout,stderr, or "what would have been printed to the screen") of your job by typing:
q -s jobNunber or (text-only)
showoutput jobNumber
You can stop your job with scancel jobnumber at any time if you want, or via the q GUI interface.
You can also do scancel -u myUserName to cancel all your jobs.
If your job runs longer than you estimated, please update your estimated runtime with the comment command, eg.
comment jobNumber "New comment"
Feel free to login to the compute node running your job and see how it's doing. Have a look at which compute nodes it's running on and then (to see node 12, for example):
ssh comp12
top
exit
If your job sits in the queue waiting for a long time
You can use the command q -tw to show information on what your job is asking for, which compute nodes match that spec., and how many are currently free. This is a good thing to run if your job hasn't started running for many minutes, to see if you're asking for too many resources (and so would have to wait a really long time for the job to start), or to have a guess at when it may start running. You can also run this with a jobnumber of 1, which will show you the current state of the nodes - how many cores & GB they have free. You could use this to see what it's possible to run before you even submit a job.
So that's the basic info for Hydra. In practice, people have problems compiling, running, and things break sometimes, so please feel free to email me (jonathan.patterson@physics.ox.ac.uk) if you have any questions / think something is wrong.
| File | Size |
|---|---|
| One-page sheet showing common cluster commands, for reference | 43.87 KB |
Categories: Theory

